

In the previous post, you learned about the general challenges of Edge AI Vision development — such as application safety and memory constraints — and how WASM helps address them. Now, let’s focus more on the AI-specific challenges.
Those who have previously worked with resource-constrained edge devices may already be familiar with some of these difficulties, as many stem from the limited memory available on such devices.
The challenges begin as soon as you decide to deploy your own model on the edge. You may have a state-of-the-art model running smoothly on your personal laptop, in the cloud, or on an Nvidia Jetson. But what if you want to achieve similar AI functionality on a much more memory-constrained device, such as a Raspberry Pi, ESP32, or another lightweight platform? First, you’ll need to prepare your model to run efficiently on such an edge device. Let’s dive into how this can be achieved.
Bringing your model to the edge
To bring an AI model to the edge, one must follow a typical workflow, starting from obtaining a floating-point model to deploying the resulting artifact on a device. This workflow is generally similar across different devices and can be divided into five key steps, which will be explained in detail. While some of these steps may be combined or even omitted depending on the device, we explicitly outline them to provide a comprehensive overview of the workflow for the IMX500 sensor.

- The first step involves obtaining a floating-point model in one of the supported AI frameworks, such as PyTorch, TensorFlow, or Keras. This can be done by building a neural network from scratch or reusing a publicly available model from GitHub or other sources. At this stage, the model should also be trained for its specific task, such as detecting people.
- The second step focuses on optimizing the floating-point model for constrained hardware using various compression techniques. This process results in a quantized model in a new format, typically .tflite or .onnx.
- In the third step, the optimized neural network model is converted into a hardware-specific binary file.
- The fourth step involves packaging this binary file to prepare it for deployment on the edge device.
- Finally, in the fifth step, the packaged model is deployed to the edge device using IoT platforms, an integrated development environment (IDE), or manual upload.
Similar workflow for other devices
To provide some intuition on how these steps apply to common edge devices, let’s examine the Raspberry Pi, Arduino, and Coral. You will notice that, for some platforms, the conversion step is integrated with optimization, as there is no need to generate a separate binary file.
All of these devices require the model to go through an optimization step, typically using a TFLite converter or, in the case of Raspberry Pi, an ONNX converter if preferred. This is the only step necessary before deploying the resulting .tflite or .onnx files onto a Raspberry Pi or Arduino.
Coral, on the other hand, requires an additional conversion step, where the Edge TPU compiler is applied to the .tflite model. Only after this step can the resulting Edge TPU .tflite file be flashed onto the Coral device.
The deployment method for the converted models depends on the specific device and may involve IoT platforms, dedicated IDEs, or a simple CLI with SSH. Once deployed, the models can be executed on the edge device as long as the corresponding TFLite or ONNX runtimes are available.
Main difference: using an intelligent vision sensor
Now that we are familiar with the general workflow for deploying an AI model on a constrained edge device, let’s take a closer look at the edge application workflow and how it changes when working with an intelligent vision sensor, IMX500, instead of a conventional camera.
When performing inference with a common (non-intelligent) camera, the sensor’s only role is to capture an image and pass it to a computing unit. The computing unit then runs the inference engine, which — depending on the device and technology stack — may involve a TFLite Interpreter, ONNX Runtime, WASI-NN, or other frameworks. Consequently, the application is responsible for handling input preprocessing, initiating, and running the inference process.
In contrast, with an intelligent vision sensor like the IMX500, inference is performed directly on a DSP (Digital Signal Processor). This means that, in addition to capturing images and transmitting them, the sensor can also provide model predictions through a separate channel. Offloading inference processing to the DSP frees up resources on the microcontrollers and mini-computers that the intelligent sensor is connected to.
As we will see later, this shift enables users to either run the same task on a more energy-efficient device or develop a more advanced application pipeline.
Restrictions on the model
With the inference logic shifted to the intelligent vision sensor, neural networks must adhere to the sensor’s specifications. In particular, there are several restrictions to keep in mind when designing a model for the IMX500.
First, only static models are supported, meaning architectures must not contain loops or conditional operations in their flow. Additionally, the model can only include supported layers, which can be identified by referring to the IMX500 layer and parameter coverage. The list of supported operations is already extensive and continues to grow.
Second, models must have a fixed input tensor size, with a maximum resolution of 640 × 640 pixels for RGB images and 1024 × 1024 pixels for monochrome images.
Finally, the converted model must be small enough to fit within the IMX500’s memory constraints, which allow 8 MB for AI operations, including model parameters and feature tensors. Notably, these limitations are similar to those encountered when working with a Coral accelerator.
While these specifications may seem restrictive, they are still sufficient to support key AI vision tasks such as image classification, object detection, pose estimation, and segmentation. Several models suitable for these tasks are publicly available in a Model Zoo for the Raspberry Pi AI camera.
Implementing an IMX500-compatible model yourself
The set of supported models is not limited to those provided by Sony and its partners. AI developers can implement their own models as long as they adhere to IMX500 restrictions. Below are some common techniques used in this process.
To begin with, if the architecture includes a backbone, it is recommended to use a lightweight alternative, such as one from the MobileNet, SqueezeNet, or ResNet family.
Secondly, most operations should be replaced with their memory-efficient counterparts. For example, a common practice in lightweight architectures is to use depth-wise separable convolutions instead of standard vanilla convolutions to reduce computational cost.
Additionally, some modules may need to be redefined — not only to incorporate the previous optimizations but also to further improve model efficiency.
Next, it is common to apply pruning to reduce model size while maintaining an optimal trade-off between performance and efficiency.
Finally, if you already have a model that fits within IMX500’s memory constraints, you can use knowledge distillation — training a smaller model to mimic a more powerful one — to enhance its performance.
While many of these techniques can be applied manually, some (such as quantization and pruning) are handled automatically by the Converter, while others are integrated into training services.
Success cases
While developing models under the aforementioned restrictions may seem like a lot of work, it enables the implementation of solutions for fascinating use cases. Let’s explore a couple of them.
Note that the focus here is not just on deploying the model to the edge but on the full solution, which leverages the power of AI and lightweight WebAssembly (WASM) applications.
- Success case – Reusing models & applications between devices: To start, let’s discuss a case we presented at Wasm I/O last year. There, we demonstrated how a model and parts of an application could be reused with WASM across devices with different architectures.
The demo setup involved two different cameras, each independently detecting moving toy cars on a race track. The first camera featured an IMX500 sensor and an ESP32 microcontroller unit with 8MB of RAM and 16MB of flash memory. The second setup consisted of a Raspberry Pi Camera 3 connected to a Raspberry Pi, equipped with 8GB of RAM and 16GB of flash storage.
The same MobileNetV2-SSD neural network was deployed on both devices, with modifications made to accommodate IMX500 during the conversion step. On the Raspberry Pi, inference was performed using WASI-NN with a .tflite model. On the ESP32 with IMX500, the converted and packaged model was flashed to the DSP (Digital Signal Processor) for execution.
For the application, we reused WASM modules across devices. Specifically, the code for fetching data from the sensor and post-processing model outputs remained unchanged. The only differences were the addition of a module to run inference on the Raspberry Pi and the need to compile the same code for different architectures.
Finally, comparing the results of the edge application across both devices revealed that they performed equally well in detecting the cars, both in terms of coordinate precision and inference speed. We concluded that this task could be efficiently solved with a small device. Moreover, when using a more powerful device, leveraging WASM with an intelligent sensor allows developers to save memory for additional application logic on the MCU.
- Success case – License plate detection & recognition PoC: Let’s now explore a more complex workflow. From the previous use case, we know that using IMX500 allows us to allocate more memory and computing resources to application logic. But what can this additional logic be used for?
One example is a two-step pipeline, where the output of one model serves as the input for another. Consider the use case of license plate detection and recognition: first, a model detects license plates, and then, for each detected plate, another model recognizes the characters.
This is precisely what we implemented in this use case. We used an IMX500 sensor together with a Raspberry Pi and two detection models — one running on the DSP and the other on the Raspberry Pi. The logic was split as follows:
- The IMX500 detected license plates and passed the inference results — detection boxes and the raw image — to the Raspberry Pi.
- The Raspberry Pi then cropped the raw image to isolate the detected license plate, ran a second network to recognize the characters, and compiled the results into a license plate number.
- Finally, the extracted license plate content was sent to an external application for visualization in a demo.
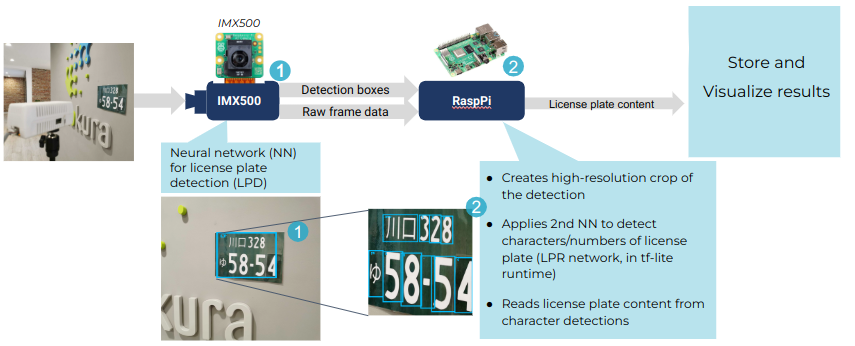
As a result, this pipeline provides license plate recognition in a single run, simplifying the workflow logic and eliminating the need to switch between models on the same device.
It is worth noting that owners of the Raspberry Pi AI Camera can implement a similar workflow on their Raspberry Pi, as all the necessary tools are now available as open source.
Edge AI Tools
Let me conclude with an introduction to the tools provided to bring your models and applications to IMX500-enabled devices as part of the AITRIOS ecosystem. The choice of tools will depend on your starting point and the desired path forward.
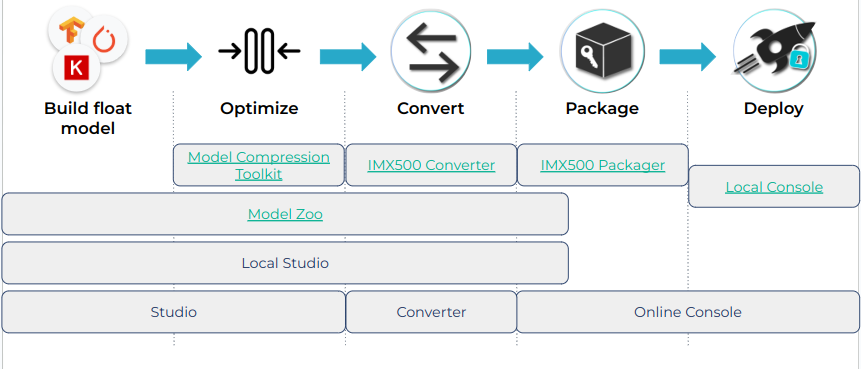
When using the open-source tools, you will need to implement an AI model yourself, following the IMX500 specifications. Then, you’ll optimize it using the Model Compression Toolkit, convert the output with the IMX500 Converter, package the resulting binary file with the IMX500 Packager, and deploy it using the Local Console.
If, instead, a user wants to try an existing model that has already been packaged for deployment on the IMX500, they can select one of the examples from the Model Zoo.
In addition to ready-to-deploy models, the ecosystem also includes a local training service, Local Studio, which generates IMX500-compatible models based on user data. While Local Studio is not an open-source product, a free trial is available for a limited time. The corresponding information can be found by the
link https://developer.aitrios.sony-semicon.com/en/studio/brain-builder
It is worth noting that users are not limited to just one workflow; they can reuse locally obtained artifacts for deployment through the Online Edition, and vice versa.
To conclude, we hope that the extensive toolkit of the AITRIOS Ecosystem will help you build and manage AI solutions at the edge. We look forward to you trying the provided tools and sharing your feedback with us.


